SQL (Lenguaje de Consulta Estructurado) es una herramienta clave para gestionar, procesar y analizar datos en bases de datos relacionales, y su uso se ha expandido a entornos de Big Data. Creado en los años 70, sigue siendo indispensable en campos como la ingeniería de datos, el análisis y la ciencia de datos.
SQL es compatible con diversas plataformas populares como SQL Server, PostgreSQL, Oracle, Google BigQuery y Databricks. Aunque trabajes con otros lenguajes como Python o R, el conocimiento de SQL es prácticamente imprescindible para cualquier profesional que trabaje con datos, ya que facilita la extracción y manipulación eficiente de información.
- Eliminar filas duplicadas
Cuando se trabaja con datos sin procesar, es común eliminar duplicados o identificar la última versión de un registro. La función de ventana ROW_NUMBER() una solución eficiente para asignar un número único a cada fila dentro de una partición de datos, según un orden específico, lo que facilita estas tareas.
WITH CTE AS (
SELECT
ID,
Nombre,
Apellido,
FechaDeNacimiento,
Edad,
Salario,
ROW_NUMBER() OVER (PARTITION BY Nombre, Apellido ORDER BY Edad DESC) AS RowNum
FROM
[BD_SPOTIFY].[dbo].[Empleados]
)
SELECT
ID,
Nombre,
Apellido,
FechaDeNacimiento,
Edad,
Salario
FROM
CTE
WHERE
RowNum = 1;- Cómo eliminar filas duplicadas con una subconsulta
Existen muchas formas de lograr el mismo resultado en SQL. Podemos utilizar una subconsulta para identificar el registro más reciente de cada grupo, seguida de una UNIÓN INTERNA para filtrar los duplicados.
with dane (id, nombre, edad, fecha) as ( select 1, 'John Smit', 19, '2020-01-01' UNION ALL select 2, 'Eva Nowak', 21, '2021-01-01' UNION ALL select 3, 'Danny Clark', 24, '2021-01-01' UNION ALL select 4, 'Alicia Kaiser', 25, '2021-01-01' UNION ALL select 5, 'John Smit', 19, '2021-01-01' UNION ALL select 6, 'Eva Nowak', 21, '2022-01-01' ) select a.* from dane a inner join ( select nombre, max(fecha) last_date from dane group by nombre ) b on a.nombre = b.nombre and a.fecha = b.last_date ;
- Cómo encontrar registros nuevos o registros que no existen
Al cargar datos de una tabla de origen, una de las tareas más habituales es identificar y cargar únicamente los registros nuevos, es decir, los registros que aún no existen en la tabla de destino. Una forma eficaz de lograrlo es utilizar el EXISTS comando SQL que permite comprobar si un registro de la tabla de origen ya existe en la tabla de destino. Si no existe, se puede insertar o procesar el registro.
Datos de prueba
Supongamos que raw_empleados es una tabla de origen y empleados es una tabla de destino.
CREATE TABLE empleados ( empleado_ID int, nombre varchar(50), apellido varchar(50), gerenteID int ); INSERT INTO empleados VALUES (1, 'Harper', 'Westbrook', NULL); INSERT INTO empleados VALUES (2, 'Liam', 'Carrington', 1); INSERT INTO empleados VALUES (3, 'Evelyn', 'Radcliffe', 1); INSERT INTO empleados VALUES (4, 'Mason', 'Albright', 2); INSERT INTO empleados VALUES (5, 'Isla', 'Whitman', 2); INSERT INTO empleados VALUES (6, 'Noah', 'Sterling', 3); INSERT INTO empleados VALUES (7, 'Ruby', 'Lennox', 3); INSERT INTO empleados VALUES (8, 'Caleb', 'Winslow', 5); INSERT INTO empleados VALUES (9, 'Avery', 'Sinclair', 6); INSERT INTO empleados VALUES (10, 'Oliver', 'Beckett', 6); CREATE TABLE raw_empleados ( empleado_ID int, nombre varchar(50), apellido varchar(50), gerenteID int ); INSERT INTO raw_empleados VALUES (1, 'Harper', 'Westbrook', NULL); INSERT INTO raw_empleados VALUES (2, 'Liam', 'Carrington', 1); INSERT INTO raw_empleados VALUES (3, 'Evelyn', 'Radcliffe', 1); INSERT INTO raw_empleados VALUES (4, 'Mason', 'Albright', 2); INSERT INTO raw_empleados VALUES (5, 'Isla', 'Whitman', 2); INSERT INTO raw_empleados VALUES (6, 'Noah', 'Sterling', 3); INSERT INTO raw_empleados VALUES (7, 'Ruby', 'Lennox', 3); INSERT INTO raw_empleados VALUES (8, 'Caleb', 'Winslow', 5); INSERT INTO raw_empleados VALUES (9, 'Avery', 'Sinclair', 6); INSERT INTO raw_empleados VALUES (10, 'Oliver', 'Beckett', 6); INSERT INTO raw_empleados VALUES (11, 'Avery', 'Sinclair', 6); INSERT INTO raw_empleados VALUES (12, 'Oliver', 'Beckett', 6);
Podemos usar el EXISTS comando para filtrar registros de la fuente que ya existen en el destino.
SELECT * FROM raw_empleados a WHERE NOT EXISTS ( SELECT 1 FROM empleados b WHERE a.empleado_ID = b.empleado_ID )
Una forma alternativa de lograr el mismo resultado es utilizar una cláusula LEFT JOIN y una WHERE . Esta consulta seleccionará registros que no existen en la tabla de destino.
SELECT a.* FROM raw_empleados a left join empleados b on a.empleado_ID = b.empleado_ID WHERE b.empleado_ID is null;
- Cómo encontrar empleados con el salario más alto
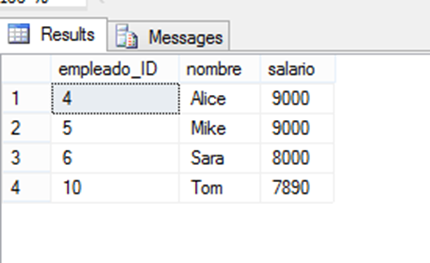
Para encontrar entidades como empleados con el salario más alto o clientes con el mayor gasto, se pueden utilizar los comandos TOP y ORDER BY. Sin embargo, ¿qué sucede si varias entidades tienen el mismo valor? Con esta combinación, es posible que no las veamos todas en los resultados. Para solucionar este problema, podemos utilizar una subconsulta, como se muestra en el siguiente ejemplo.
WITH empleados (empleado_ID, nombre, salario) AS (
SELECT 1, 'John', 5000
UNION ALL
SELECT 2, 'Jane', 7000
UNION ALL
SELECT 3, 'Bob', 4500
UNION ALL
SELECT 4, 'Alice', 9000
UNION ALL
SELECT 5, 'Mike', 9000
UNION ALL
SELECT 6, 'Sara', 8000
UNION ALL
SELECT 7, 'Tom', 6000
UNION ALL
SELECT 8, 'Lucy', 5500
UNION ALL
SELECT 9, 'Mary', 5820
UNION ALL
SELECT 10, 'Tom', 7890
)
SELECT
a.*
FROM empleados a
INNER JOIN (
select distinct top 3 salario from empleados order by salario desc
) as b
on a.salario = b.salario;Como puedes observar, nuestro objetivo era recuperar tres empleados con los salarios más altos, pero como dos de ellos tienen el mismo salario, ambos deberían incluirse en el resultado.
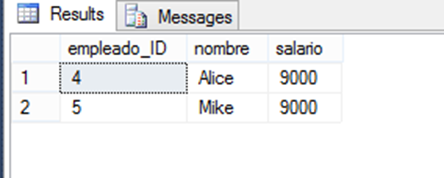
- Uso de la función MAX con una subconsulta
Para recuperar los empleados que tienen el salario más alto, puede utilizar la función MAX para encontrar el salario máximo y luego utilizar una subconsulta para filtrar los empleados que ganan ese salario.
WITH empleados (empleado_ID, nombre, salario) AS (
SELECT 1, 'John', 5000
UNION ALL
SELECT 2, 'Jane', 7000
UNION ALL
SELECT 3, 'Bob', 4500
UNION ALL
SELECT 4, 'Alice', 9000
UNION ALL
SELECT 5, 'Mike', 9000
UNION ALL
SELECT 6, 'Sara', 8000
UNION ALL
SELECT 7, 'Tom', 6000
UNION ALL
SELECT 8, 'Lucy', 5500
UNION ALL
SELECT 9, 'Mary', 5820
UNION ALL
SELECT 10, 'Tom', 7890
)
SELECT
a.*
FROM
empleados a
INNER JOIN (
select max(salario) salario from empleados
) as b
on a.salario = b.salario;Resultado:
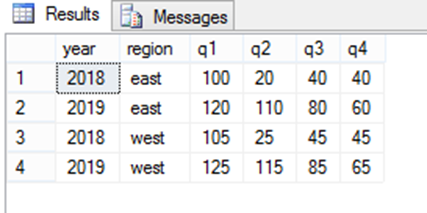
- PIVOT
El operador PIVOT en SQL Server transforma filas en columnas, permitiendo reorganizar y resumir datos para facilitar el análisis. Se utiliza cuando quieres agrupar datos por ciertas categorías y mostrar resultados en un formato más legible, como una tabla dinámica, aplicando funciones de agregación como SUM, COUNT o AVG.
WITH data (year, quarter, region, value) AS (
SELECT 2018, 1, 'east', 100 UNION ALL
SELECT 2018, 2, 'east', 20 UNION ALL
SELECT 2018, 3, 'east', 40 UNION ALL
SELECT 2018, 4, 'east', 40 UNION ALL
SELECT 2019, 1, 'east', 120 UNION ALL
SELECT 2019, 2, 'east', 110 UNION ALL
SELECT 2019, 3, 'east', 80 UNION ALL
SELECT 2019, 4, 'east', 60 UNION ALL
SELECT 2018, 1, 'west', 105 UNION ALL
SELECT 2018, 2, 'west', 25 UNION ALL
SELECT 2018, 3, 'west', 45 UNION ALL
SELECT 2018, 4, 'west', 45 UNION ALL
SELECT 2019, 1, 'west', 125 UNION ALL
SELECT 2019, 2, 'west', 115 UNION ALL
SELECT 2019, 3, 'west', 85 UNION ALL
SELECT 2019, 4, 'west', 65
)
SELECT year, region, [1] AS q1, [2] AS q2, [3] AS q3, [4] AS q4
FROM data
PIVOT (
SUM(value)
FOR quarter IN ([1], [2], [3], [4])
) AS pivoted_data;El resultado:
- Comparar Row-to-Row: LAG Función
La función LAG en SQL Server permite comparar valores entre filas consecutivas en una tabla, accediendo al valor de una fila previa sin necesidad de usar un self-join. Es útil para análisis como calcular diferencias, detectar cambios o identificar tendencias en datos ordenados, ya que devuelve el valor de una columna específica desde una posición anterior en el conjunto de resultados. Se combina con la cláusula OVER para definir el orden en que se evalúan las filas.
WITH moneda (fecha, precio, moneda) AS (
SELECT CAST('2006-01-02' AS DATE), 3.2582, 'USD'
UNION SELECT CAST('2006-01-03' AS DATE), 3.2488, 'USD'
UNION SELECT CAST('2006-01-04' AS DATE), 3.1858, 'USD'
UNION SELECT CAST('2006-01-05' AS DATE), 3.1416, 'USD'
UNION SELECT CAST('2006-01-06' AS DATE), 3.1507, 'USD'
UNION SELECT CAST('2006-01-09' AS DATE), 3.1228, 'USD'
UNION SELECT CAST('2006-01-10' AS DATE), 3.128, 'USD'
UNION SELECT CAST('2006-01-11' AS DATE), 3.1353, 'USD'
UNION SELECT CAST('2006-01-12' AS DATE), 3.1229, 'USD'
UNION SELECT CAST('2006-01-13' AS DATE), 3.1542, 'USD'
)
SELECT
fecha,
moneda,
precio,
LAG(precio) OVER (ORDER BY fecha) AS precio_del_dia_anterior,
(precio - LAG(precio) OVER (ORDER BY fecha)) / LAG(precio) OVER (ORDER BY fecha) AS variacion
FROM moneda;Resultados:

- La función LEAD
La función lead, es una herramienta de análisis de datos en SQL que permite comparar un registro actual con el siguiente registro dentro de un conjunto de datos. Esto es especialmente útil para identificar tendencias o cambios a lo largo del tiempo, como detectar aumentos, disminuciones o cambios entre periodos consecutivos.
LEAD es una función de ventana que te permite “mirar hacia adelante” en tu conjunto de datos.
with currency (date, price, currency) as (
select cast('2006-01-02' as date) ,3.2582, 'USD'
UNION select cast('2006-01-03' as date) ,3.2488 , 'USD'
UNION select cast('2006-01-04' as date) ,3.1858 , 'USD'
UNION select cast('2006-01-05' as date) ,3.1416 , 'USD'
UNION select cast('2006-01-06' as date) ,3.1507 , 'USD'
UNION select cast('2006-01-09' as date) ,3.1228 , 'USD'
UNION select cast('2006-01-10' as date) ,3.128 , 'USD'
UNION select cast('2006-01-11' as date) ,3.1353 , 'USD'
UNION select cast('2006-01-12' as date) ,3.1229 , 'USD'
UNION select cast('2006-01-13' as date) ,3.1542 , 'USD'
)
select
date,
currency,
price,
lead(price) over (order by date) previose_day_price
from
currencyResultado:

- La función NTILE
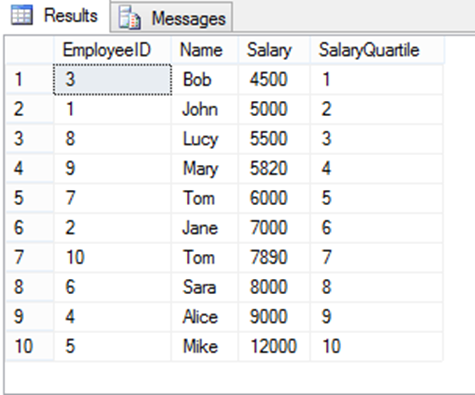
Es una función de ventana que divide un conjunto de datos en un número específico de grupos con un tamaño lo más informe posible. Esto es útil para el análisis como dividir datos en cuartiles, facilitando la identificación de tendencias o patrones en los datos.
WITH Employees (EmployeeID, Name, Salary) AS (
SELECT 1, 'John', 5000
UNION ALL SELECT 2, 'Jane', 7000
UNION ALL SELECT 3, 'Bob', 4500
UNION ALL SELECT 4, 'Alice', 9000
UNION ALL SELECT 5, 'Mike', 12000
UNION ALL SELECT 6, 'Sara', 8000
UNION ALL SELECT 7, 'Tom', 6000
UNION ALL SELECT 8, 'Lucy', 5500
UNION ALL SELECT 9, 'Mary', 5820
UNION ALL SELECT 10, 'Tom', 7890
)
SELECT
EmployeeID,
Name,
Salary,
NTILE(10) OVER (ORDER BY Salary) AS SalaryQuartile
FROM Employees;Resultado: